プレスリリース
|
ATR音声言語通信研究所(社長:山本誠一、関西文化学術研究都市 国際電気通信基礎技術研究所内)は、
成蹊大学森島研究室と共同で、
音声翻訳システムにより対象言語に翻訳された音声に合わせて使用者の発話顔画像の口元を動かすことにより、
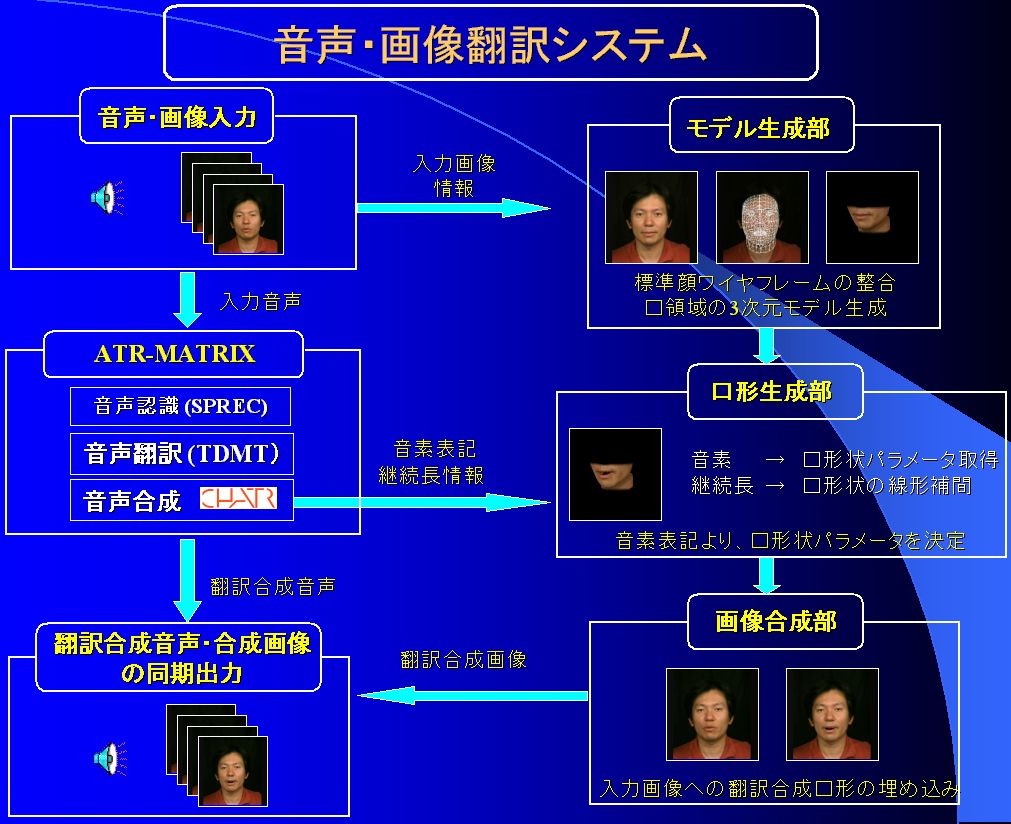
音声だけでなく、発話顔も翻訳するマルチモーダル翻訳技術を開発しました。 Face-to-Faceのコミュニケーションにおいて、顔は言葉とともに、さまざまなメッセージを伝えており、 人間は音声情報だけでなく、 画像情報など多様な情報を統合しながら頑健かつ柔軟に処理していることが知られています。 異なる言語間では、意思疎通のために言葉を翻訳する必要がありますが、それに合わせて顔の情報を合成できれば、 より自然で親しみのあるコミュニケーションが実現できます。 映画などの吹き替えでは、音声のみを翻訳しているため、口の動きと発話内容が一致しないという課題があります。 また、顔画像全体をコンピュータグラフィックスにより合成すると、 言葉以外の情報を伝えることができなくなってしまいます。 そこで、ATR音声言語通信研究所では、 従来から進めてきた声質を保ったまま他国語に翻訳した音声を合成する研究に加え、 複数の情報(モダリティー)を統合する研究を行ってきました。本技術は、 音声合成と併せて口の動きだけを翻訳することにより、自然な画像を合成するものです。 自然な翻訳を実現するためには、本人の声質や、表情を保つことが望まれます。 そこで、声質を保ったまま他国語に翻訳した音声を合成する方法についての研究を進めています。 更に、本研究では、表情を保ったまま口の動きを合成する研究を課題としています。 異なる言語では発音の方法が異なる場合があります。 たとえば日本語から英語への翻訳では、日本語にはない数種類の母音や子音の口の動きを合成する必要があります。 また、合成口形を出力する際は、合成音声との時間同期が不可欠であり、同期に関する精密な制御が必要となります。 表情を保つためには、 口やその周囲以外は本人の原言語発話時の顔動画像をそのまま用いることによって実現しています。 この際、色や大きさはもとより、顔の位置や向きを正確に合わせて合成しなければ、 非常に不自然な画像となってしまいます。 そこで、本技術では、まず、一般的な顔の3次元モデルを用意し、 発音に対応した動きを話者に依存しない形で用意します。次に、入力話者の顔画像に3次元モデルを適合させ、 翻訳後の音声の音素、音素継続長情報を利用して発話口形画像を合成します。 この発話口形画像を元の原言語発話顔の口の部分に埋め込み、これにより、本人の声質と顔の特徴を保ったまま、 翻訳された内容を話すことを実現しました。 本技術は、自然に発話された対話の音声・画像のマルチモーダル翻訳を初めて実現したものです。 今回の試作システムは、日本語、英語間の双方向翻訳を実装し、本技術の効果を検証するものですが、 今後、より広範囲に適用するために、 多数の言語間のマルチモーダル翻訳をリアルタイムで実現するシステムの開発を進めています。 |
| 音声・画像翻訳システム図 |
 |
※(株)ATR音声言語通信研究所は、2001年に研究プロジェクトを終了しています。